
 4 марта, 2015
4 марта, 2015  rius
rius 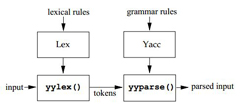
В данной заметке я рассмотрю использование связки lex + yacc (с небольшими доработками указания справедливы и для flex + Bizon).
В свое время я перелопатил много статей по синтаксическому разбору, но большинство из них (самые частые — переводные статьи про установку температуры нагревателя) не объясняют как расправиться с рекурсией или сделать чтение из файла вместо используемых по умолчанию стандартных потоков ввода/вывода. Как только встает задача разбора какого-то языка со своими правилами, а не простого конфигурационного файла, то возникает множество вопросов.
Если вы не собираетесь менять поведение умолчанию (чтение из stdin), то запуск синтаксического анализатора будет такой:
cat text_file | ./binary |
или
./binary < text_file |
Блок, отвечающий за чтение из файла вместо stdin:
if (argc < 2) { printf("usage: %s <input file="">\n", argv[0]); } extern FILE *yyin; yyin = fopen( argv[1], "r" ); |
С ним бинарник можно запускать так:
./binary text_file |
Исходники целиком в тексте заметки публиковать не буду, они всё загромоздят. Скачать исходники можно по ссылке: исходники в архиве
Для локализации ошибок в разбираемом файле используются переменные:
current_line_number — номер строки, начинается с 1
current_pos — позиция символа в строке, начинается с 1
При встрече символа перевода строки увеличивается на 1 current_line_number, а при встрече какого-то иного токена значение увеличивается на длину токена.
Это средство не претендует на абсолютную точность при указании позиции ошибки (тут много погрешностей из-за того, что обход происходит рекурсивно). Но, тем не менее, оно даст намек на место в файле, которое не понравилось анализатору. А это уже не мало, когда пытаешься понять, где же ошибка: в исходниках анализатора или файле, который подвергается разбору. Если захотите сделать свой компилятор для упрощенного языка программирования, то так можно будет сохранять место объявления переменной (идентификатор).
Разбираться будут строки вида: {ddddd; {aaaa; ffff}; {qqq; rr; 777}}.
Т.е. перечисления слов, чисел и перечислений, разделитель — точка с запятой. Это даст возможность поработать с рекурсией.
Как и в программном коде, тут есть смысл раскидать значения по строкам, чтоб получать указание на строку и сужать круг подозреваемых операторов:
{ddddd;
{aaaa;
ffff;
ssss};
{qqq;
rr;
777}
} |
В разбираемом файле мы ищем слова (WORD) и целые числа (NUMBER). Т.е. Очередной токен может быть и числом и словом:
typedef enum {wordType, numberType} dataType; typedef struct Value{ dataType type; union { int ivalue; char *svalue; } u; } Value; |
(см. datastructure.h)
Мы используем перечисление для указания типа данной Value — type, а в union используем общую память для хранения конкретного типа — целого числа или указателя. Тип из перечисления нужен для понимания того, что именно хранится в union при обращении. Если вы неправильно интерпретируете его содержимое, то получите core dump.
В файле для lex эта структура используется так:
[a-zA-Z]+ { yylval.GenericValue.u.svalue = strdup(yytext); yylval.GenericValue.type=wordType; increase_pos_by(strlen(yytext)); return WORD; } [0-9]+ { yylval.GenericValue.u.ivalue = atoi(yytext); yylval.GenericValue.type=numberType; increase_pos_by(strlen(yytext)); return NUMBER; } |
Т.е. мы присваиваем значения в union-e yylval, а именно полям структуры с псевдонимом GenericValue. Фактический тип для GenericValue задается в union, см. ниже.
Для обработки правил нашего языка используется этакий си-шный полиморфизм — union. В этом блоке вы будете задавать псевдонимы для тех типов данных, которые назначите разным токенам и даже правилам разбора:
%union { struct Value GenericValue; // объявляем типы данных для правил разбора statementNodePtr stmtType; enumerationNodePtr enumerationType; elementNodePtr elType; }; // это и есть yylval |
(см. файл sample.y, после кодогенерации этот кусочек будет в конце файла y.tab.h) В данном блоке мы перечисляем типы данных для вершин нашего дерева синтаксического разбора, которые одновременно являются и правилами в sample.y.
Разберем описание одного из правил – enumeration. Оно может быть пустым, состоять из одного элемента или быть перечислением элементов:
enumeration:
{
//пустое перечисление
$ = createEnumerationNode(NULL, NULL);
}
|
element
{
$ = createEnumerationNode(NULL, $1);
}
|
enumeration SEMICOLON element
{
$ = createEnumerationNode($1, $3);
}
; |
$$ — это псевдоним самой вершины, и если enumeration будет использоваться как составная часть другого правила, то там будет использоваться именно присвоенное значение (указатель). $1 и $3 в последнем блоке — это части в строке «enumeration SEMICOLON element», нумерация начинается с 1.
В том же файле sample.y немного выше мы описываем вершину дерева этого типа:
%type <enumerationtype> enumeration </enumerationtype> |
И еще выше определяем, что есть enumerationType:
enumerationNodePtr enumerationType; |
Далее смотрим файл datastructure.h:
typedef struct enumerationNode *enumerationNodePtr; typedef struct enumerationNode{ elementNodePtr element; enumerationNodePtr next; // связный список } enumerationNode; |
Для создания вершины нужна функция:
enumerationNodePtr createEnumerationNode(enumerationNodePtr next, elementNodePtr element){ enumerationNodePtr retval = (enumerationNodePtr) malloc(sizeof(struct enumerationNode)); retval->next = next; retval->element = element; return retval; } |
Остальные типы вершин создаются аналогично.
Функция createEnumerationNode() формирует в итоге связный список, признак конца — у очередной вершины next == NULL. В функции вызван malloc(), значит без соответствующего free() будет утечка памяти.
Для закрепления пройденного в исходниках решается такая задача. В результате разбора файла надо сформировать строку, которая формируется по рекурсивному правилу:
Строковое значение перечисления — это перемешанные случайным образом строковые значения его элементов. Строковое значение слова — само слово. Строковое значение числа — пустая строка.
Тестовый файл:
{ddddd;
{aaaa; ffff};
{qqq; rr; 777}
} |
Пример выполнения:
[root@dmitry lex_for_outofrange]# ./sample sample_input.txt ddddd, aaaa, ffff, rr, qqq [root@dmitry lex_for_outofrange]# ./sample sample_input.txt aaaa, ffff, ddddd, qqq, rr [root@dmitry lex_for_outofrange]# ./sample sample_input.txt ddddd, ffff, aaaa, qqq, rr [root@dmitry lex_for_outofrange]# ./sample sample_input.txt ddddd, aaaa, ffff, qqq, rr [root@dmitry lex_for_outofrange]# ./sample sample_input.txt ddddd, aaaa, ffff, rr, qqq [root@dmitry lex_for_outofrange]# ./sample sample_input.txt qqq, rr, aaaa, ffff, ddddd |
Вся работа происходит в этих функциях:
// Функции для обходя дерева и обработки вершин char* processStatement(statementNodePtr root){ char *str = processEnum(root->ePtr); return str; } char* processEnumElement(elementNodePtr element){ if (element == NULL) { // пропускаем пустые элементы return NULL; } switch(element->type){ case value: switch (element->u._value.type) { case wordType: //printf("type word %s\n", element->u._value.u.svalue ); return element->u._value.u.svalue; break; case numberType: //printf("type number %d\n", element->u._value.u.ivalue ); return NULL; // для чисел ничего не выводим break; default: break; } break; case statement: //printf("type statement\n" ); // recursion again return processStatement(element->u.stmt); break; default: printf("unexpected type, exiting\n" ); exit (0); } } char* processEnum(enumerationNodePtr list){ // we are handling here a linked list if (list != NULL){ if (list->next != NULL) { // рекурсия, идем в конец связного списка char *strList = processEnum(list->next); // строка представляет собой аккумулированое строковое значение части дерева int lenStrList = strlen(strList); char *strElement = processEnumElement(list->element); // строка представляет собой последний элемент в списке ; if (strElement) { int lenStrElement = strlen(strElement); int r = rand() % 2; if (r == 1) { // Forming a line as follows: strList + delimiter + strElement strList = (char*) realloc (strList, sizeof(char)* (lenStrList + lenStrElement + 2)); strcpy (strList + lenStrList , delimiter); strcpy (strList + lenStrList + 2, strElement); return strList; } else { // Формирование итоговой строки: strElement + delimiter + strList // нельзя использовать strElement как dest, Это испортит значение в вершине char* strTemp = (char*) malloc (sizeof(char)* (lenStrList + lenStrElement + 2 )); strcpy (strTemp, strElement); strcpy (strTemp + lenStrElement, delimiter); strcpy (strTemp + lenStrElement + 2, strList); return strTemp; } } else { return strList; } } else { // сюда попадаем, если вершина тупиковая char *str = processEnumElement(list->element); return str; } } } |
Сам разбор инициируется в main() (файл sample.y):
if (root) { // sanity check char *str = processStatement(root); // распечатываем перемешанные строки printf("%s\n", str); } |
Не забывайте, что все вызовы malloc()/realloc() без соответствующего free() приводят к утечкам памяти. В данной заметке я не касаюсь вопроса очистки памяти в дереве разбора (yacc подчищает только свои огрехи). Оставляю это пытливому читателю 🙂
Скачать исходники можно по ссылке (дублирую для тех, кто привык читать по диагонали): исходники в архиве
 Posted in
Posted in  Tags:
Tags: