
 25 марта, 2015
25 марта, 2015  rius
rius Использование именованных каналов и замены процессов
Данная заметка является вольным переводом этой статьи
http://vincebuffalo.com/2013/08/08/the-mighty-named-pipe.html
Трудно не влюбиться в Unix, если вы биоинформатик. В прошлой заметке я упоминал о том, что каналы в Unix представляют собой элегантный способ взаимодействия биоинформационных программ (и вообще осуществляют взаимодействие между процессами). Исследуя другие способы сопряжения программ в Unix я открыл два из них, которым уделяют недостаточно внимания: именованные каналы и замена процессов.
Почему мы любим каналы и Unix
Некоторое время назад я был озадачен лекцией Гари Бернхардта Unix — это бензопила. Аналогия Бернхардта с бензопилой великолепна: люди иногда боятся выполнять действия в Unix из-за того, что это могучий инструмент. А при работе с могучим инструментом легко напортачить. Я думаю, что в процессе освоения Unix не редок вопрос: «Это умно и элегантно? Или это в конец тупо?». Это нормально, особенно если вы переходите от языка Lisp или Python (или даже C). Unix – это система ориентированная на результат. Я пользовался бензопилой и было поражен одновременно двумя вещами: 1. как легко она проходит через дерево и 2. что я достаточно глуп для того, чтоб использовать это страшилище в трех футах от своих жизненно важных органов. Это и есть Unix.
У Бернхардта есть замечательный слайд, который как нельзя лучше отражает отношение биоинформатиков к каналам:

Каналы замечательны. Любые две (грамотно написанные) программы могут общаться в Unix. Вся громоздкость и сложность взаимодействия процессов решается одним символом, | . Спасибо Дугу МкЛрою и остальным. Поток обычно является простым текстом, универсальным интерфейсом, но он необязательно такой. При использовании потоков неважно что именно передается: данные разделенные табуляцией, случайный текст электронного письма или 100 миллионов нуклеотидов. Каналы — это грандиозный, красивый и элегантный компонент бензопилы Unix.
Но элегантность этой программной абстракции сама по себе не смогла бы завоевать сердца тысяч системных администраторов, программистов и ученых, важно указать и то, что каналы быстры. Накладные расходы при использовании каналов невысоки, и уж во всяком случае каналы более эффективны, чем чтение/запись на жесткий диск. Каналы масштабируются под достаточно большие объемы данных и они запросто соединяются. Сопряжение программ таким образом позволяет проверять промежуточный вывод, менять потоки данных и даже отводить копию потока я помощью утилиты tee.
Где нельзя применить каналы
Каналы в Unix восхитительны, но они не всегда срабатывают. Классической проблемой будет ситуация вроде этой:
program --in1 in1.txt --in2 in2.txt --out1 out1.txt \ --out2 out2.txt > stats.txt 2> diagnostics.stderr |
Мои предыдущие коллеги и я написали ряд инструментов для обработки продвинутых данных и попали в такую ситуацию. Ради соблюдения традиций Unix мы сделали каждый инструмент автономным. На практике это было ключевым решением в дизайне, потому как мы видели большие различия в качестве данных из-за использования различных библиотек. При сопряжении программ это дало наряду с юниксовостью еще и больше возможностей по поиску проблемных мест.
Однако, данный шаг (вызов программы) в нашем потоке подразумевает 2 файла на входе и 3 файла на выходе — всё из-за природы наших данных. Вдобавок оба файла in1.txt и in2.txt являются результатами работы другой программы, и она может работать одновременно с той, которую мы видим в примере. Классические каналы не помогут, т.к. у нас более одного входного и выходного файла: наша абстракция канала разбита. Хакерское решение использовать standard error (stderror) видится неприятным. Что же делать?
Именованные каналы
Именованные каналы являются одним из решений. Именованный канал, известный также как FIFO (First In First Out, концепция в программировании), является особым типом файла, который мы можем создать с помощью команды mkinfo:
$ mkfifo fqin $ prw-r--r-- 1 vinceb staff 0 Aug 5 22:50 fqin |
Вы можете заметить, что у файла в действительности особый атрибут: p, сокращение от pipe. С помощью них можно соединять ввод/вывод программ, как если бы это были файлы:
$ echo "hello, named pipes" > fqin & [1] 16430 $ cat < fqin [1] + 16430 done echo "hello, named pipes" > fqin hello, named pipes |
Я надеюсь, что вы увидите всю мощь несмотря на простоту примера. Несмотря на то, что синтаксис выглядит как перенаправление в файл, в действительности на жесткий диск ничего не пишется. Заметьте также, что строка «[1] + 16430 done» появилась из-за того, что мы запустили фоновый процесс (для того, чтобы освободить терминал). Вместо этого можно было запустить еще одно окно терминала. Для удаления именованного канала используется команда rm.
Использование двух именованных каналов позволяет предотвратить бутылочное горлышко — IO операции — и состыковать программы создав in1.txt и in2.txt в самой программе, но я хочу более ясного решения. Для быстрого взаимодействия процессов я не хочу использовать многократно mkfifo и удалять созданные каналы. К счастью в Unix есть более элегантный способ: замена процесса.
Замена процесса
При замене процесса используется тот же механизм, что и в именованных каналах, но при этом не нужно создавать фактически существующий на жестком диске канал. Из-за этого их часто называют анонимными именованными каналами. Замена процесса реализована в большинстве современных командных оболочек. Оболочка выполняет эти команды, и передает вывод в файловый дескриптор, который в Unix системах будет примерно таким /dev/fd/11. Этот файловый дескриптор будет затем подставлен командной оболочкой вместо вызова <(). Запуск команды в скобках порождает отдельный подпроцесс, то есть несколько вызовов <( ) автоматически выполняются параллельно (планирование выполняется средствами ОС, так что используйте это осторожно в многопользовательских системах, где предпочтительнее явное указание числа процессов). К тому же будучи процессом, содержимое вызова <() может иметь свои собственные каналы, так что не удивляйтесь такому: <(command arg1 | othercommand arg2. Это возможно и иногда разумно. В нашем примере это будет так:
program --in1 <(makein raw1.txt) --in2 <(makein raw2.txt) \ --out1 out1.txt --out2 out2.txt > stats.txt 2> diagnostics.stderr |
Здесь makein – это программа, которая создает in1.txt и in2.txt в первоначальной команде (из raw1.txt и raw2.txt) и выводит их в стандартный поток. Это действительно настолько просто: процесс выполняется в своей подоболочке, и его стандартный вывод уходит в файловый дескриптор (/dev/fd/11 или что-то похожее в вашей ОС), и program принимает это на входе. Фактически, если посмотреть данные о процессе с помощью команд htop или ps, то мы увидим:
$ ps aux | grep program vince [...] program --in1 /dev/fd/63 --in2 /dev/fd/62 --out1 out1.txt --out2 out2.txt > stats.txt 2> diagnostics.stderr |
Но, допустим, что нам надо передать out1.txt и out2.txt в архивированном (зазипованном) виде. Мы не хотим писать на жесткий диск, это отнимает ресурсы системы. К счастью замена процесса работает и в обратную сторону: >(). Поэтому можно пережать данные на лету:
program --in1 <(makein raw1.txt) --in2 <(makein raw2.txt) \ --out1 >(gzip > out.txt.gz) --out2 >(gzip > out2.txt.gz) > stats.txt 2> diagnostics.stderr |
Unix икогда не перестанет удивлять меня своей мощью. Бензопила завелась и вы распиливаете огромное дерево. Но мощь достается по своей цене: потеря ясности. Отладка таких вещей сложна. Уровень сложности напоминает дрожжи: я не рекомендую накладывать слишком толстый слой сразу. Вложенность процессов опрятна, но не так проста и читабельна как канал |.
Скорость
Так, и это действительно быстрее работает? Так точно. Операции чтения/записи на диск затратны — смотрим данные о задержках, которые должен знать каждый программист. К сожалению, у меня нет времени на обширное исследование производительности, но я написал немного чокнутый скрипт https://gist.github.com/vsbuffalo/6181676 , который использует замену процесса. Вы можете воспользоваться им на свой страх и риск. Один из тестов использует trim.sh, второй является простым скриптом, запускающим Scythe в фоне (параллельно, с использованием wait) и пишущим на диск, а Sickle обрабатывает. Измерение производительности имеет предубеждение против замены процесса (дает фору сопернику замены процесса), потому что я в тестах с заменой я еще и архивирую с помощью >(gzip > ), а в другом тесте — нет. Несмотря на простую методику тестирования разницу трудно не заметить:
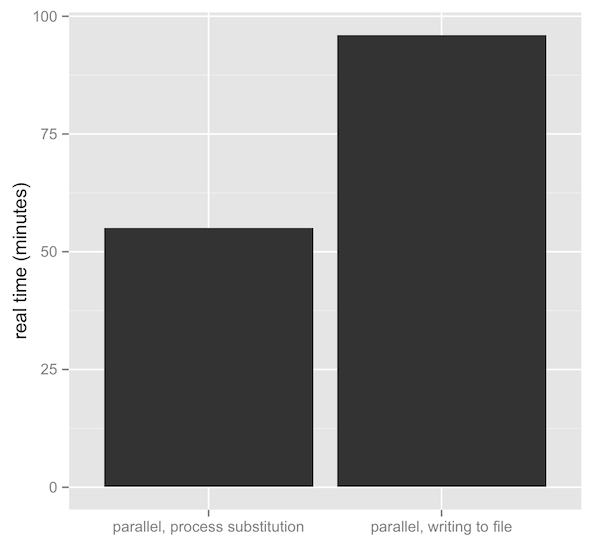
К тому же при использовании >(gzip > ) наши последовательности данных получили сжатие в 3.46%, что неплохо. Большинство наших программ-инструментов справляются с gzip данными сами по себе (в том смысле, что не нужна предварительная распаковка), поэтому при сжатии на лету из-за замены процесса нет смысла хранить большие объемы данных сжатыми. Это особенно полезно в области биоинформатики, где мы имеем скромные коэффициенты сжатия, и наши друзья less, cat и grep имею аналоги: zless, gzcat, zgrep.
Повторюсь, я потрясен красотой и мощью Unix. Насколько я знаю, замена процесса не является широко известной — я спросил несколько друзей-сисадминов, и оказалось, что она видели именованные каналы, но не замену процесса. Учитывая абстракции файлов в Unix это неудивительно. В общем-то Брайан Керниган высказался поэтично про именованные каналы и Unix в этом классическом видео: http://techchannel.att.com/play-video.cfm/2012/2/22/AT&T-Archives-The-UNIX-System Надеюсь, что новые поколения программистов будт открывать для себя всю красоту Unix (и прекратят изобретать велосипед, в чем мы все иногда грешны). Инструменты, созданные для работы в среде Unix могут поднять Unix на небывалую высоту с невероятной силой.
Если вам интересна тема именованных каналов, я рекомендую:
— Посмотрите пример с командой tee и остальные примеры в Википедии Process substitution
— Посмотрите статью 1997 года про именованные каналы http://www.linuxjournal.com/article/2156
 Posted in
Posted in  Tags:
Tags: